IO管理和磁盘调度
一、IO功能的组织
程序控制IO:处理器代表一个进程给IO模块发送一个命令,进程进入忙等待,直到操作完成
中断控制IO:处理器代表一个进程给IO模块发送一个命令,若IO是非阻塞的,处理器继续执行进程,若是阻塞的,进程被置为阻塞态。
直接内存访问(DMA):一个DMA模块控制内存和IO模块之间的数据交换。处理器给DMA发请求,且只有在整个数据块传输完毕后,它才被中断。
在IO设备发展的历程中,cpu逐步从IO任务中解脱,提高了性能。现在IO模块有自己的处理器和局部存储器,本质上就是一个计算机,受cpu调度。
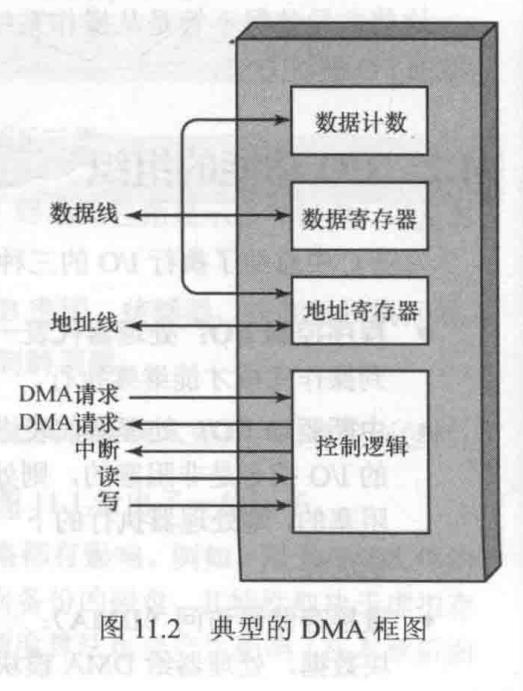
1.直接内存访问(DMA)
DMA单元能模拟cpu,且实际上能像cpu一样获得系统总线的控制权。
工作流程:1.处理器通过读写控制线发送读或写信号
2.通过数据线传输相关IO设备地址、读写的起始地址(存在地址寄存器里)、读写长度(存在数据计数寄存器里)
3.处理器进行其他工作,DMA模块和IO设备进行交互,数据传输结束后,DMA给处理器发送中断信号。
使用DMA,只有数据传送开始和结束的时候才需要cpu
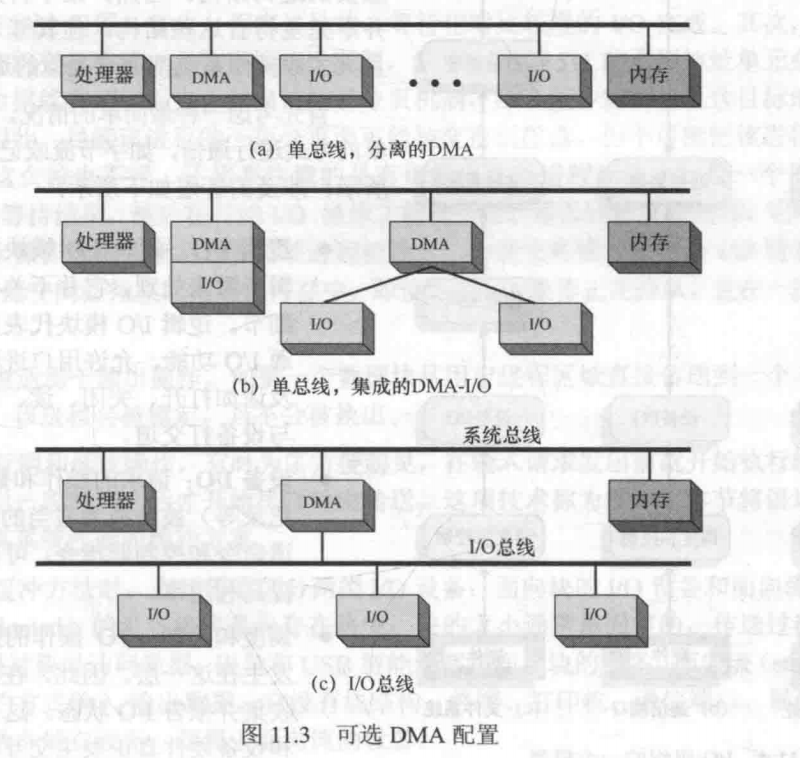
DMA配置方式
二、IO缓冲
缓冲 IO 也被成为标准 IO,大多数的文件系统系统默认都是以缓冲 IO 的方式来工作的。在Linux的缓冲I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
接下来我们看看缓冲 IO 下读写操作是如何进行?
- 读操作:
操作系统检查内核的缓冲区有没有需要的数据,如果已经缓冲了,那么就直接从缓冲中返回;否则从磁盘中读取到内核缓冲中,然后再复制到用户空间缓冲中。
- 写操作:
将数据从用户空间复制到内核空间的缓冲中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
缓冲I/O的优点:
- 在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
- 因为内核中有缓冲,可以减少读盘的次数,从而提高性能。
- 可以平滑IO需求的峰值
缓冲I/O的缺点:
在缓冲 I/O 机制中,DMA 方式可以将数据直接从磁盘读到内核空间页缓冲中,或者将数据从内核空间页缓冲直接写回到磁盘上,而不能直接在用户地址空间和磁盘之间进行数据传输,这样数据在传输过程中需要在应用程序地址空间(用户空间)和内核缓冲(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
三、磁盘调度
1. FCFS 调度(先来先服务)
磁盘调度的最简单形式当然是先来先服务(FCFS)算法。虽然这种算法比较公平,但是它通常并不提供最快的服务。
例如,考虑一个磁盘队列,其 I/O 请求块的柱面的顺序如下:
98,183,37,122,14,124,65,67
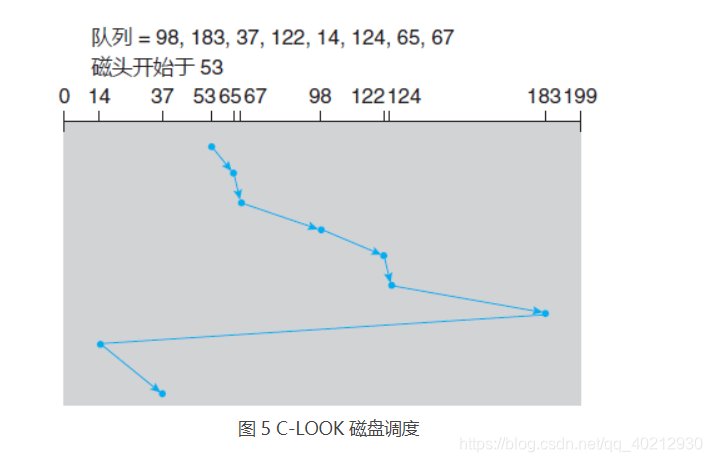
如果磁头开始位于柱面 53,那么它首先从 53 移到 98,接着再到 183、37、122、14、124、65,最后到 67,磁头移动柱面的总数为 640。这种调度如图 1 所示。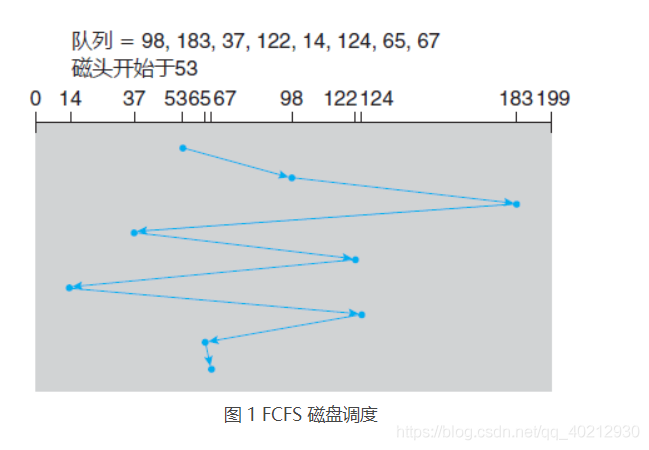
从 122 到 14 再到 124 的大摆动说明了这种调度的问题。如果对柱面 37 和 14 的请求一起处理,不管是在 122 和 124 之前或之后,总的磁头移动会大大减少,并且性能也会因此得以改善。
2.SSTF调度(最短寻道时间优先)
在移动磁头到别处以便处理其他请求之前,处理靠近当前磁头位置的所有请求可能较为合理。这个假设是最短寻道时间优先(SSTF)算法的基础。
SSTF 算法选择处理距离当前磁头位置的最短寻道时间的请求。换句话说,SSTF 选择最接近磁头位置的待处理请求。
对于上面请求队列的示例,与开始磁头位置(53)的最近请求位于柱面 65。一旦位于柱面 65,下个最近请求位于柱面 67。从那里,由于柱面 37 比 98 还要近,所以下次处理 37。如此,会处理位于柱面 14 的请求,接着 98,122,124,最后183(图 2)。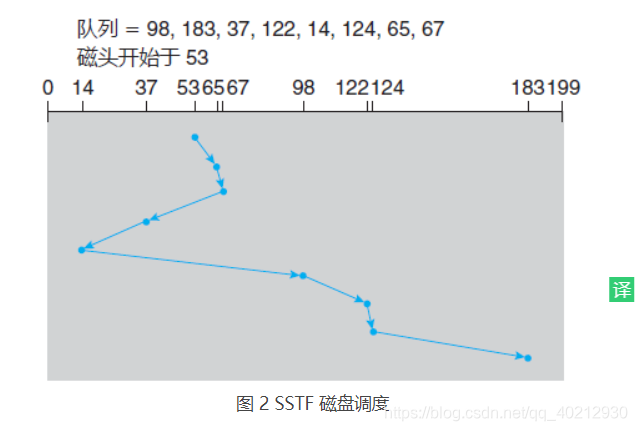
这种调度算法的磁头移动只有 236 个柱面,约为 FCFS 调度算法的磁头移动总数的三分之一多一点。显然,这种算法大大提高了性能。
SSTF 调度本质上是一种最短作业优先(SJF)调度;与 SJF 调度一样,它可能会导致一些请求的饥饿。请记住,请求可能随时到达。假设在队列中有两个请求,分别针对柱面 14 和 186,而当处理来自 14 的请求时,另一个靠近 14 的请求来了,这个新的请求会下次处理,这样位于 186 的请求需要等待。当处理该请求时,另一个 14 附近的请求可能到达。
理论上,相互接近的一些请求会连续不断地到达,这样位于 186 上的请求可能永远得不到服务。当等待处理请求队列较长时,这种情况就很可能出现了。
虽然 SSTF 算法比 FCFS 算法有了相当改进,但是并非最优的。对于这个例子,还可以做得更好:移动磁头从 53 到 37(虽然 37 并不是最近的),再到 14,再到 65、67、98、122、124、183。这种策略的磁头移动的柱面总数为 208。
3. SCAN 调度(电梯算法)
对于扫描算法,磁臂从磁盘的一端开始,向另一端移动;在移过每个柱面时,处理请求。当到达磁盘的另一端时,磁头移动方向反转,并继续处理。磁头连续来回扫描磁盘。SCAN 算法有时称为电梯算法,因为磁头的行为就像大楼里面的电梯,先处理所有向上的请求,然后再处理相反方向的请求。
下面回到前面的例子来说明。在采用 SCAN 来调度柱面 98、183、37、122、14、124、65 和 67 的请求之前,除了磁头的当前位置,还需知道磁头的移动方向。
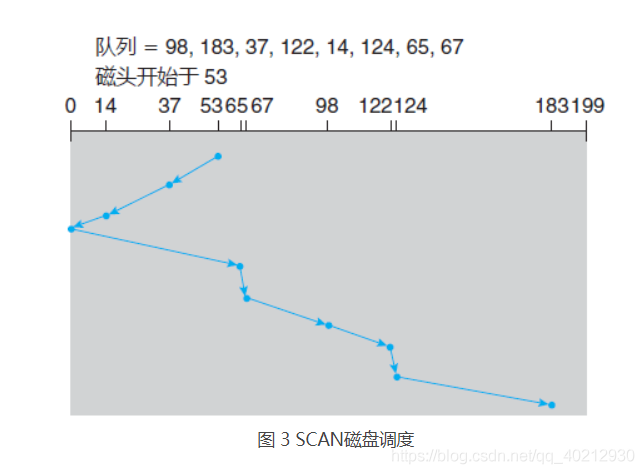
假设磁头朝 0 移动并且磁头初始位置还是 53,磁头接下来处理 37,然后 14。在柱面 0 时,磁头会反转,移向磁盘的另一端,并处理柱面 65、67、98、122、124、183(图 3)上的请求。如果请求刚好在磁头前方加入队列,则它几乎马上就会得到服务;如果请求刚好在磁头后方加入队列,则它必须等待,直到磁头移到磁盘的另一端,反转方向,并返回。
假设请求柱面的分布是均匀的,考虑当磁头移到磁盘一端并且反转方向时的请求密度。这时,紧靠磁头前方的请求相对较少,因为最近处理过这些柱面。磁盘另一端的请求密度却是最多。这些请求的等待时间也最长,那么为什么不先去那里?这就是下一个算法的想法。
4. C-SCAN 调度(循环扫描)
对于扫描算法,磁臂从磁盘的一端开始,向另一端移动;在移过每个柱面时,处理请求。当到达磁盘的另一端时,磁头移动方向反转,并继续处理。磁头连续来回扫描磁盘。SCAN 算法有时称为电梯算法,因为磁头的行为就像大楼里面的电梯,先处理所有向上的请求,然后再处理相反方向的请求。
下面回到前面的例子来说明。在采用 SCAN 来调度柱面 98、183、37、122、14、124、65 和 67 的请求之前,除了磁头的当前位置,还需知道磁头的移动方向。
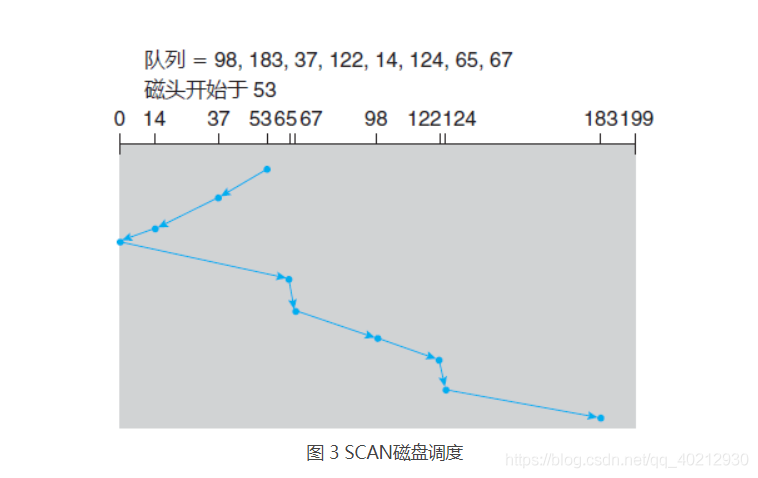
C-SCAN 调度算法基本上将这些柱面作为一个环链,将最后柱面连到首个柱面。
5. LOOK 调度
正如以上所述,SCAN 和 C-SCAN 在磁盘的整个宽度内移动磁臂。实际上,这两种算法通常都不是按这种方式实施的。更常见的是,磁臂只需移到一个方向的最远请求为止。
遵循这种模式的 SCAN 算法和 C-SCAN 算法分别称为 LOOK 和 C-LOOK 调度,因为它们在向特定方向移动时查看是否会有请求(图 5)。