TCP拥塞控制
1.拥塞控制是什么?
拥塞控制是TCP连接的每一方都要进行的行为,它通过算法预测网络线路上的拥塞情况,根据拥塞情况来调整和指导数据的发送。
2.为什么要有拥塞控制?
要讲拥塞控制,首先要讲明白拥塞。所谓拥塞,是路由器因无法处理高速率到达的流量而被迫丢弃数据信息的现象。这里要特别注意区别拥塞控制和窗口管理的区别,窗口管理是基于TCP连接双方的,双方根据各自应用层处理数据的速率来协调发送窗口和接受窗口。而拥塞控制是基于整个网络的,它的目的是尽可能地缓解网络上出现的拥塞现象。
3.如何进行拥塞控制
拥塞控制的核心是:当检测到网络拥塞时,减缓数据的发送速率。在发送端引人一个窗日控制变量,确保发送窗口大小不超过接收端接收能力和网络传输能力,即TCP发送端的发送速率等于接收速率和传输速率两者中较小值。这个窗口称为拥塞窗口(cwnd)
SMSS:TCP报文段的最大长度(仅指数据部分)
1.慢启动
当一个新的TCP连接建立或检测到由重传超时(RTO)导致的丢包时,需要执行慢启动。何为慢启动?慢启动实际上是对拥塞窗口的大小控制算法,它先将cwnd设置成一个较小值(通常为最大段大小和最大传输单元中的较小值),每当收到一个ACK包,表明网络情况允许当前发送速率,cwnd就可以尝试进行扩大。因此,在接收到一个数据段的ACK后,通常cwnd值会增加到2,接着会发送两个数据
段。如果成功收到相应的新的ACK, cwnd会由2变4,由4变8,以此类推,直到cwnd == 接收窗口。
前所述, cwnd会随着RTT呈指数增长。因此,最终cwnd会增至很大,大量数据包的发送将导致网络瘫痪(TCP吞吐量与,RTT成正比)。当发生上述情况时, cwnd大幅度减小(减至原值一半)。这是TCP由慢启动阶段至拥塞避免阶段的转折点,与cwnd和慢启动阂sIowstart threshold,ssthresh)相关。
2.拥塞避免
为了得到更多的传输资源而不致影响其他连接传输, TCP实现了拥塞避免算法。一旦确立慢启动阈值, TCP会进人拥塞避免阶段, cwnd每次的增长值近似于成功传输的数据段大小。将指数增长转为线性增长。
慢启动阈值的设定
慢启动闹值的初始值可任意设定(如awnd或更大),这会使得TCP总是以慢启动状态开始传输。当有重传情况发生,无论是超时重传还是快速重传, ssthresh=maX (当前发送窗口大小/2, 2*SMSS)
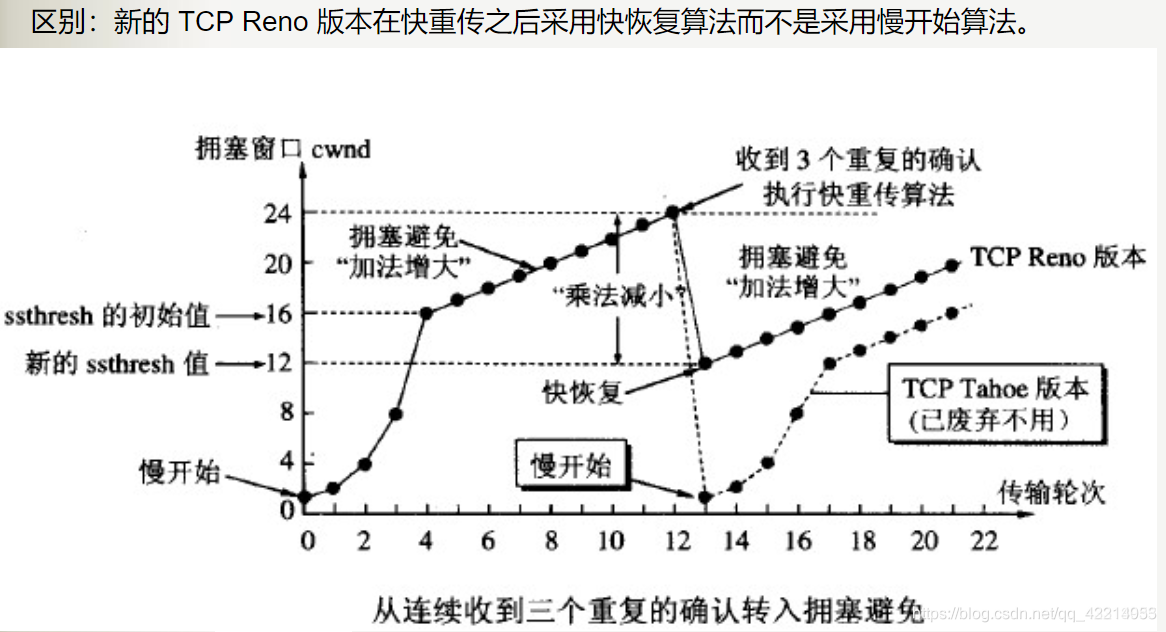
3.快速恢复
快速恢复机制一般和快速重传机制同时使用。
当发送端收到第三个重复确认的报文时,会更新ssthresh的值,然后立即重传丢失的报文段,并且设置:cwnd = ssthresh+3*SMSS,进入拥塞避免阶段。当收到一个重复确认的报文时,设置cwnd = cwnd +SMSS。此时发送端可以发送新的TCP报文(如果新的cwnd允许)当收到新数据的确认时,设置cwnd=ssthresh。进入拥塞避免阶段。这里的新数据表示新的报文,而不是丢失的报文。
在旧的tcp拥塞控制算法中,快速重传之后会进入慢启动阶段,而新的tcp拥塞控制算法在快速重传之后进入快速恢复阶段。